本蒟蒻这几天因为std::vector的巨大时空常数吃了不少亏。所以在此进行一些分析。
我用vector的仅有的两个原因是与其他STL的高度兼容和range-based for的简洁语法。这是前向星无法具备的。
有一种广泛流传的错误观点认为vector的任意位置insert是\(O(\sqrt{n})\)的,实际上是线性的。实际测试表明,3e5次头部insert耗时4.077s(real time,下同),6e5次耗时16.060s。相比较而言,在1e5次插入时性能逊色于vector的__gnu_cxx::rope,插入1e6个数只需3.845s(rope在头部插入好像是\(O(1)\)的,只花了0.234s)。
vector的clear不能释放内存。resize也不行。我已经做过实验了。两种正确的做法:
第一种需要大括号,很丑陋:{vector<int> t;v.swap(t);}
第二种可以逗号,但是长:v.clear(),v.shrink_to_fit();
另外,vector的建立是相当耗时的。由于push_back会非常智障的频繁动态申请内存,建一棵1e6个点的随机树需要0.224s。对于CF1137C这样的5e6个点的图论题,光把分层图(及反图)建出来,1.368s已经过去,不被卡常就怪了。不开O2的话更是运行了3.018s。相比较,前向星使用了可以忽略不计的0.091s。这是因为vector分配了8814097次内存。
结论:图论题少用vector。
2019-03-16 UPD:
存在加速方法!
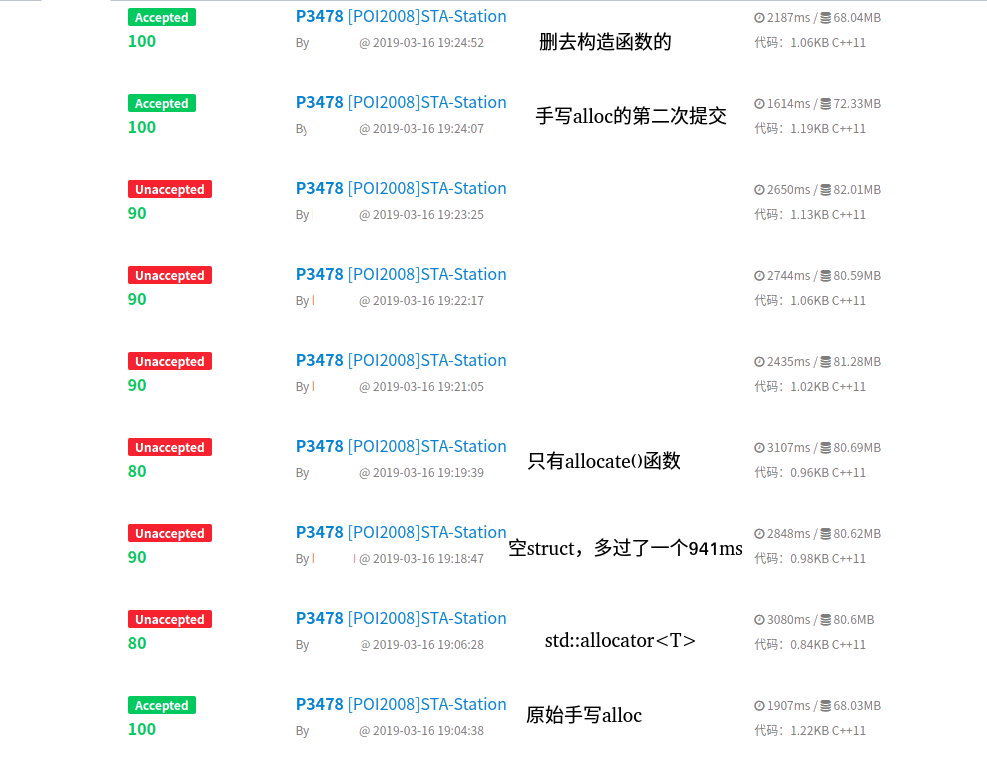
今天看了一个神仙的洛谷日报(将来时),学到了卡常方法。我早就知道可以手写allocator,之前我一直以为这是没有什么用的工程知识,现在却发现这是STL党的福音。将代码进行社会主义改造后如下:
char _[3<<25],*sp=_;
template<class T> struct alloc:allocator<T>{
// alloc(){}
// template<class T2> alloc(const alloc<T2> &a){}
// template<class T2> alloc<T>& operator=(const alloc<T2>&a){return*this;}
template<class T2> struct rebind{typedef alloc<T2> other;};
inline T* allocate(size_t n){
T* result=(T*)sp;sp+=n*sizeof(T);
return result;
}
inline void deallocate(T* p,size_t n){}
};
这里有一个奇怪的情况:把任意几个成员函数删掉(甚至变成空struct),都可以编译成功并且输出正确结果,只不过是不能起到优化作用而已(还不如不写)。
关键是deallocate,allocate和rebind函数,对于速度提升缺一不可。暂且没有理解三个构造函数的作用(因为看起来删掉之后也一模一样)。
使用方法:vector<int,alloc<int>> v;
效果如下(一百万的树,建树+dfs两次刚好不T):